Die ReAl-Computerarchitektur
ReAl = Ressourcen-Algebra
|
|
|
|
Worum es geht: Um einen alternativen Ansatz der Rechnerarchitektur:
Statt dessen:
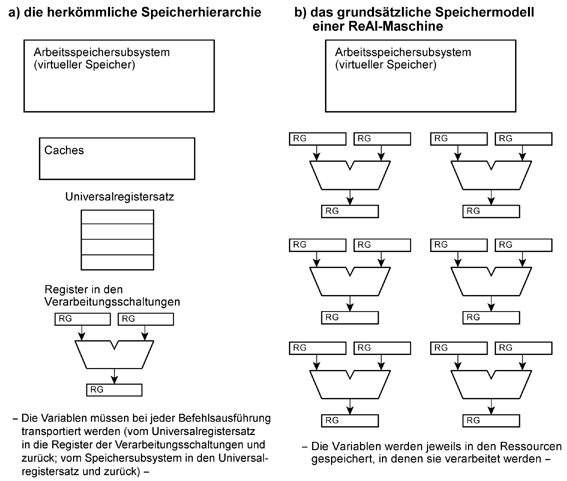
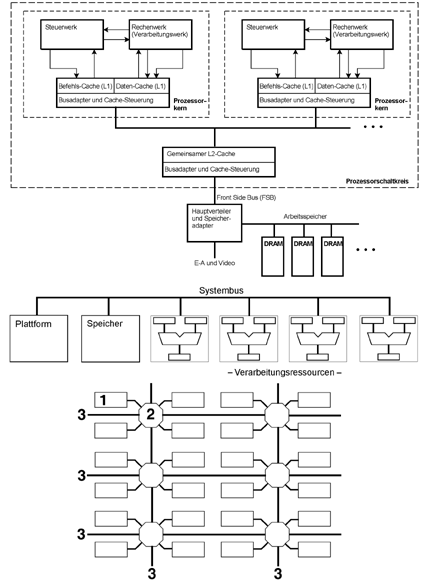
Kerne oder Ressourcen? Weshalb müssen es immer ganze Prozessoren sein? Lange Zeit war der Prozessor etwas Kostbares. Meistens konnte man sich nur einen einzigen leisten. Heute bringt man so viele Prozessoren auf einem einzigen Schaltkreis unter, daß es offensichtlich schwerfällt, mit ihnen etwas Vernünftiges anzustellen. Eine grundsätzliche Alternative Die interne Befehlsschleife wird aufgetrennt. Die Software koordiniert keine autonomen befehlsgesteuerten Zustandsautomaten, sondern elementare RTL-Anordnungen, wie Arithmetik-Logik-Einheiten, Adreßrechenwerke usw., die auf dem Schaltkreis ein Gewebe vergleichsweise einfacher Ressourcen bilden. ReAl ist die grundsätzliche Programmschnittstelle (API), die solche Anordnungen steuern kann. Letzten Endes sollen keine konfigurierbaren FPGAs herauskommen, sondern hart verdrahtete, frei programmierbare Maschinen... Vom Universalprozessor zur ReAl-Maschine
Zurück zu den Grundlagen -- wie funktioniert eigentlich ein Prozessor?
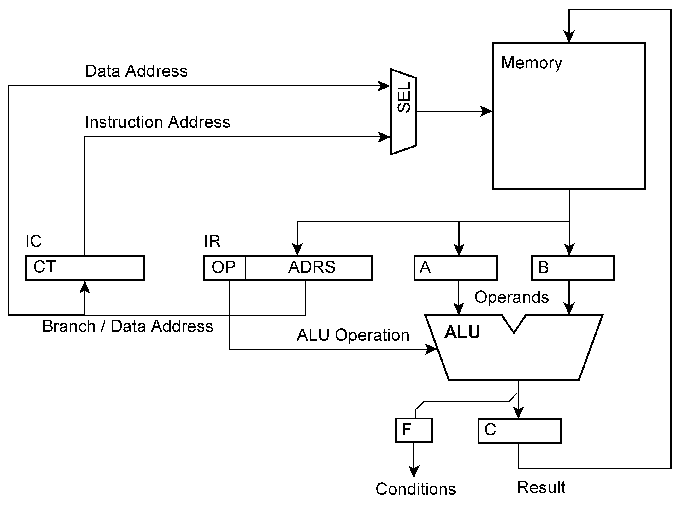
Ein ganz einfacher Prozessorkern. Der Prozessor ist ein autonomer Zustandsautomat. Der Folgezustand hängt von einer Auswahl aus dem aktuellen Speicherinhalt ab. Diese Auswahl ist gegeben durch die Befehlsadresse und die Datenadresse. Mehrere Prozessorkerne Umn sie auszunutzen, müssen sie nicht nur mit Arbeit versorgt werden (Parallelisierung), sondern es ist auch erforderlich, die Programmabläufe aufeinander abzustimmen (Synchronisation). Das läuft darauf hinaus, den Programmablauf von außen zu beobachten und zu beeinflussen. Aber wo kann man ansetzen?
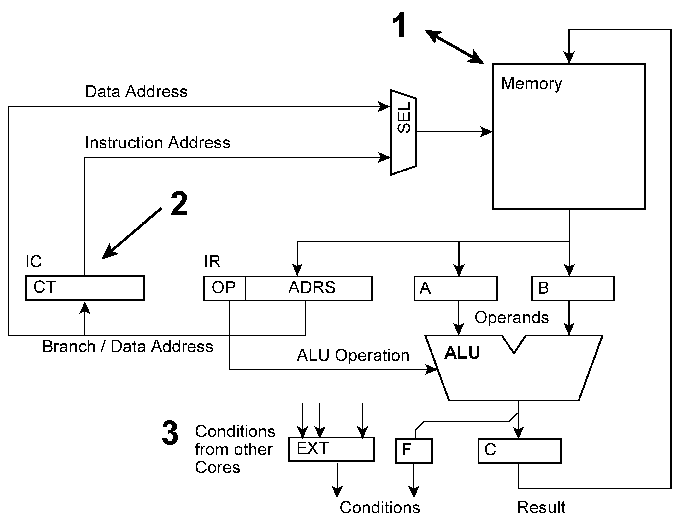
1 -- Auslesen und Ändern des Speicherinhalts. Der Speicher braucht zwei Zugriffswege. Das kostet entweder Zeit (Multimaster-Bussystem, Speichervermittlung) oder Schaltungsaufwand (Dual-Port-Organisation). Die Latenzzeiten sind hoch, da eine Änderung des Speicherinhalts den Programmablauf nur dann beeinflussen kann, wenn die betreffenden Speicherwörter auch vom Programm adressiert werden; wenn also das Programm gleichsam an diesen Speicherwörten vorbeikommt. 2 -- Auslesen der Befehlsadresse und Ändern des Befehlsablaufs. Das erstere wäre mit Vergleichsschaltungen o. dergl. zu erledigen, das letztere durch Unterbrechungsauslösung, Einspeisen von Befehlsadressen usw. Wenn das halbwegs vernünftig funktionieren soll, darf die Maschine aber keine Pipelines haben, vor allem keine tiefen. 3 -- Signalisieren und Auswerten von Bedingungen. Das ist schaltungstechnisch einfach, erfordert aber spezielle Befehle. Die Latenzzeiten sind vergleichsweise hoch. Weitere Möglichkeiten bestehen im Anhalten von Takten, im Einführen von Wartezuständen oder in einer globalen Steuerung des gesamten Systems, wobei zwischen Ausführungs- und Kommunikationsphasen zyklisch umgeschaltet wird. Wenn die einen Prozessoren viel zu tun haben und die anderen wenig, ist der gesamte Apparat nicht richtig ausgelastet. Prozessoren, die gerade nichts zu tun haben, als zusätzliche Caches zu nutzen oder sie damit zu beschäftigen, Programmstücke auf gut Glück (= spekulativ) auszuführen (all das ist in der Literatur vorgeschlagen worden), kann man im Grunde nur als Verlegenheitslösungen bezeichnen, die unnötig viel CO2 ausstoßen. Man kann nicht nur durch Abschalten Strom sparen, sondern vor allem auch durch Vermeiden unnötiger Schaltvorgänge. Die Idealvorstellung: ein jeder Schaltvorgang in der Maschine trägt tatsächlich zur Lösung des jeweiligen Anwendungsproblems bei (Implementierungseffizienz).
Mal was Neues ausprobieren . . . Die derzeit gängigen Prozessoren beruhen auf Architekturprinzipien, die in den 70er und 80er Jahren entwickelt wurden. (Das betrifft sinngemäß auch die Betriebssysteme und Programmiersprachen.) Seinerzeit war die Hardware knapp. Allen Entwurfsentscheidungen (welche architekturseitigen Vorstellungen werden verwirklicht, welche nicht?) mußte stets die Realisierbarkeit im Rahmen der jeweiligen Technologie zugrunde gelegt werden. Die heutigen Halbleitertechnologien ermöglichen es, mehrere herkömmliche Hochleistungsprozessoren auf einem einzigen Schaltkreis anzuordnen. Es ergibt sich die Frage, ob man diese Möglichkeiten nicht auch nutzen sollte, um etwas radikal Neues auszuprobieren . . . Lohnt es sich, die Architektur des herkömmlichen Universalrechners weiter zu verbessern? - Kann sein, aber . . . In der Praxis hat bisher immer die Technologie die Leistung gebracht - architekturseitige Verbesserungen waren nur selten wirklich entscheidend. Die eigentlichen Wundertaten werden vom Silizium, von den Compilern und von den Algorithmen verrichtet . . . Architekturseitige Verbesserungen haben einen viel geringeren Effekt als die Weiterentwicklungen der Techologie:
Deshalb ein anderer Ansatz: Es ist genügend da (nicht wie bei armen Leuten . . .):
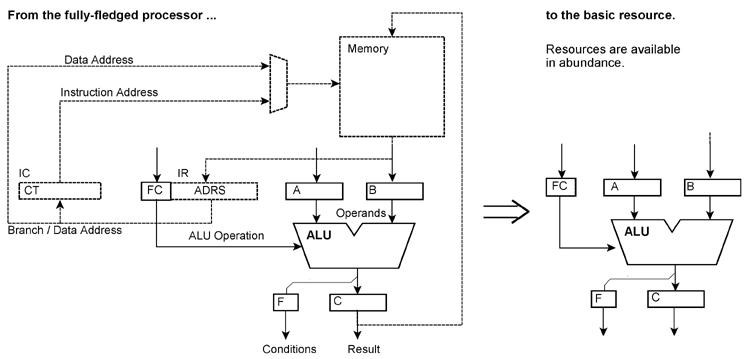
Unser Grundmodell: Wenn wir irgend etwas tun wollen, so holen wir ein dazu geeignetes Stück Hardware aus einem Lager (wie einen Hammer, um einen Nagel einzuschlagen, einen Schraubenschlüssel, um eine Mutter festzuziehen usw.) und verwenden es für die auszuführende Informationswandlung. Wenn wir zwei Zahlen zueinander addieren wollen, holen wir einen Addierer, wenn wir zwei Werte miteinander vergleichen wollen, einen Vergleicher usw. Ein Stück Hardware, das seine Arbeit getan hat, wird in das Lager zurückgestellt. In Weiterführung der Analogie holen wir für unsere Arbeit soviele Werkzeuge, wie wir jeweils brauchen, z. B. 50 Hämmer, wenn 50 Nägel einzuschlagen, oder 50 Addierer, wenn 50 Zahlenpaare zueinander zu addieren sind. Unsere Architekturdefinition umfaßt eine Menge von Ressourcen und eine Menge von Datenstrukturen. Ressourcen führen bestimmte Operationen über Daten bestimmter Strukturen aus. Diese Abbildung konstituiert im Grunde eine algebraische Struktur. Deshalb wird die Architektur mit ReAl = Ressourcen-Algebra bezeichnet. Das Modell einer Ressource ist eine Hardware, die bestimmte Informationswandlungen ausführt, also aus gegebenen Daten (an den Eingängen) neue Daten (an den Ausgängen) errechnet. Allgemeine Annahmen und Entwicklungsziele:
Wir tun so, als ob sich für jede x-beliebige Informationswandlung eine Hardware bauen ließe (und entscheiden dann fallweise, was tatsächlich als Hardware gebaut wird und was nicht). Diese (fiktive) Hardware kann zur Laufzeit dynamisch auf-, um- und abgebaut werden. Die Maschinenbefehle der ReAl-Architektur betreffen keine bestimmten Operationen, sondern das Auf-, Um- und Abbauen von Ressourcen, die zugehörigen Datentransporte (Parameterversorgung) und das Aktivieren der betreffenden Ressourcen. Um eine bestimmte Programmierabsicht auszuführen, werden jeweils geeignete Ressourcen aus der Menge aller Ressourcen (dem Ressourcenvorat) ausgewählt. Diese werden mit Parametern versorgt. Dann werden die Verarbeitungsvorgänge in den Ressourcen ausgelöst. Anschließend werden die Ergebnisse zugewiesen (Endergebnisse werden gespeichert oder ausgegebenen, Zwischenergebnisse an andere Ressourcen weitergeleitet). Weitere Schritte der Parameterversorgung, Auslösung und Zuweisung werden so oft durchlaufen, bis die jeweilige Verarbeitungsaufgabe ausgeführt ist. Schließlich werden die nicht mehr benötigten Ressourcen an den Ressourcenvorrat zurückgegeben. Diese Abläufe werden durch Programme gesteuert. Die Programmsteuerung beruht auf speziellen Maschinenbefehlen, den sog. Operatoren. Besondere Operatoren ermöglichen es, Verbindungen zwischen Ressourcen einzurichten (die Ressourcen miteinander zu verketten) und solche Verbindungen wieder zu trennen. Ist eine Verbindung (Verkettung) zwischen Ressourcen eingerichtet, laufen die Schritte der Parameterversorgung, des Auslösen der Verarbeitungsvorgänge und des Zuweisens der Ergebnisse innerhalb der verketteten Ressourcen selbsttätig ab. Durch Verketten von Ressourcen kann man - je nach Bedarf - fiktive Spezialprozessoren bauen, die dem Datenflußschema der jeweiligen Verarbeitungsaufgabe entsprechen. Die Architekturprinzipien können implementiert werden:
Verarbeitungsschaltungen können in Speicheranordnungen eingebettet werden (Ressourcenzellen, aktive Speicheranordnungen), so daß sich kürzeste Zugriffswege ergeben. Diese Vereinfachungen der Hardware bieten die Möglichkeit, die Taktfrequenz zu erhöhen, Pipeline-Stufe einzusparen (Verkürzung der Latenzzeiten der Operationsausführung) und auf einer gegebenen Schaltkreisfläche mehr bzw. leistungsfähigere Verarbeitungsschaltungen anzuordnen. Da der inhärente Parallelismus unmittelbar aus der Programmierabsicht heraus (in statu nascendi) erkannt wird, ist es möglich, ggf. auch hunderte Verarbeitungswerke gleichzeitig einzusetzen, um den Ablauf des einzelnen Programms zu beschleunigen. Je nach den Kosten- und Leistungszielen und nach dem Stand der Technologie sind Hard- und Software gegeneinander austauschbar (z. B. ein Unterprogramm gegen eine spezielle Verarbeitungseinrichtung und umgekehrt). Entsprechende Programme sind somit invariant gegen die technologische Entwicklung; sie können jeden Fortschritt der Schaltungsintegration ausnutzen. Auf programmierbaren Schaltkreisen sind Systeme realisierbar, die eine im Grunde beliebige Kombinationen von Hard- und Software darstellen. Anwendungspraktisch wichtige Zusatzfunktionen, z. B. die Unterstützung des Fehlersuchens (Debugging), der Systemverwaltung, der Datenverschlüsselung usw., die herkömmlicherweise zusätzliche Programmabläufe (Geschwindigkeitsverlust) oder spezielle Hardware (Aufwand) erfordern, können in die Ressourcen organisch eingebaut werden. Auf Grundlage der ReAl-Wirkprinzipien sollen verschiedene Arten künftiger Computersysteme entwickelt werden:
Die Auslegung gemäß den ReAl-Wirkprinzipien ermöglicht:
Das ReAl-Programmiermodell läßt sich auch in Compilern anwenden. Ein typischer Entwicklungsgang: Formulieren der Programmierabsicht (in einer beliebigen Programmiersprache) => Wandlung in den Code einer fiktiven Maschine nach ReAl-Architekturprinzipen => Umsetzung in den Maschinencode der Zielarchitektur => Programmausführung. Es ist bisher üblich, den Quellcode zunächst in einen fiktiven Maschinencode umzusetzen. Solche fiktiven (virtuellen) Maschinen sind zumeist als Stackmaschinen ausgelegt. Stackmaschinen arbeiten aber inhärent sequentiell. Demgegenüber haben gemäß den ReAl-Architekturprinzipen ausgelegte fiktive Maschinen vor allem folgende Vorteile:
Fiktive (virtuelle) Maschinen auf Grundlage der ReAl-Architektur können als Gegenstück zur bekannten Java Virtual Machine (JVM) angesehen werden (Tabelle 1). JVM ist - im Verbund mit der Programmiersprache Java - vor allem für kleinere Programme (Applets) vorgesehen. Hierfür ist die Kompaktheit des Codes von besonderer Bedeutung. In einem kompakten Maschinencode läßt sich aber die Parallelverarbeitung nicht beschreiben. Die ReAl-Architektur betrifft hingegen die oberen Leistungsbereiche. Hier kommt es vor allem darauf an, den inhärenten Parallelismus so gut wie möglich auszunutzen. Mit den Operatoren der vorgeschlagenen Architektur kann der einem Programmablauf inhärente Parallelismus in vollem Umfange dargestellt werden. Zudem ist es möglich, Programmabläufe in Datenflußschemata und fiktive (virtuelle) Spezialhardware umzusetzen.
Tabelle 1 Java Virtual Machine (JVM) vs. ReAl Ein auf der ReAl-Architektur beruhendes Programm kann die Programmierabsicht in allen wesentlichen Einzelheiten beschreiben; wenn es sein muß, bis hin zur einzelnen Booleschen Gleichung. Deshalb ist zu erwarten, daß sich solche Programme ohne weiteres in Maschinencode für künftige Systeme umsetzen lassen (Zukunftssicherheit). Die Architekturprinzipen können ausgenutzt werden, um Anwendungen zu unterstützen, an die hohe Sicherheitsanforderungen gestellt werden. Es seien zunächst zwei Möglichkeiten genannt:
Kennzeichnend ist die Auflösung der Prozessorstrukturen in die einzelnen Funktionseinheiten und der fließende Übergang zwischen Hard- und Software. Die festen - proprietären - Prozessorarchitekturen, Betriebssysteme und Anwendungsprogramme können durch Ressourcen an sich beliebiger Herkunft ersetzt werden (aufgelöste Systemarchitektur). Sowohl System- als auch Anwendungsfunktionen werden von Ressourcen erbracht, die beliebiger Herkunft sein und wahlweise als Hardware oder als Software ausgeführt werden können. Wesentlich hierfür ist, daß die Operatoren nur das Aufrufen, Aktivieren usw. der Ressourcen beschreiben, während die eigentlichen funktionellen Wirkungen im Innern der jeweiligen Ressource erbracht werden.
|
|
|
|
Aktuelles: 5. Januar 2026
Zellen, Kerne und Ressourcen. Artikel in Circuit Cellar, December 2016: Resource Algebra and the Future of FPGA Technology Zum Ansehen und Herunterladen (PDFs): IDAACS 2007 Presentation (PDF) Verarbeitungsleistung, Stromaufnahme und Implementierungseffizienz Eine vorläufige Beschreibung (120 Seiten) Auszüge daraus: Ein einführender Text in englischer Sprache (25 Seiten) Kapitel 1 der vorläufigen Beschreibung in Englisch (Stand: 02/07) Kapitel 5 der vorläufigen Beschreibung in Englisch (Stand: 02/07) Kapitel 6 der vorläufigen Beschreibung in Englisch (Stand: 02/07) Kapitel 7 der vorläufigen Beschreibung in Englisch (Stand: 02/07) Kapitel 8 der vorläufigen Beschreibung in Englisch (Stand: 02/07) Ältere Texte: Hardware Resources: A Generalizing View on Computer Architectures (1990). How many operation units are adequate? (1991) A Next Generation Superscalar Architecture (1990). Patentanmeldungen:
|